Concepts Overview#
SIERRA's core concepts build on each other. This page explains how they fit together; the linked pages go deeper on each one.
The Short Version#
You define what to vary (experimental design), SIERRA instantiates that variation as a batch of experiments (batch criteria), runs the batch through a five-stage pipeline (Pipeline), writes everything to a predictable directory tree (Runtime Directory Tree), and passes data between stages according to a consistent dataflow model (Dataflow Across Pipeline Stages).
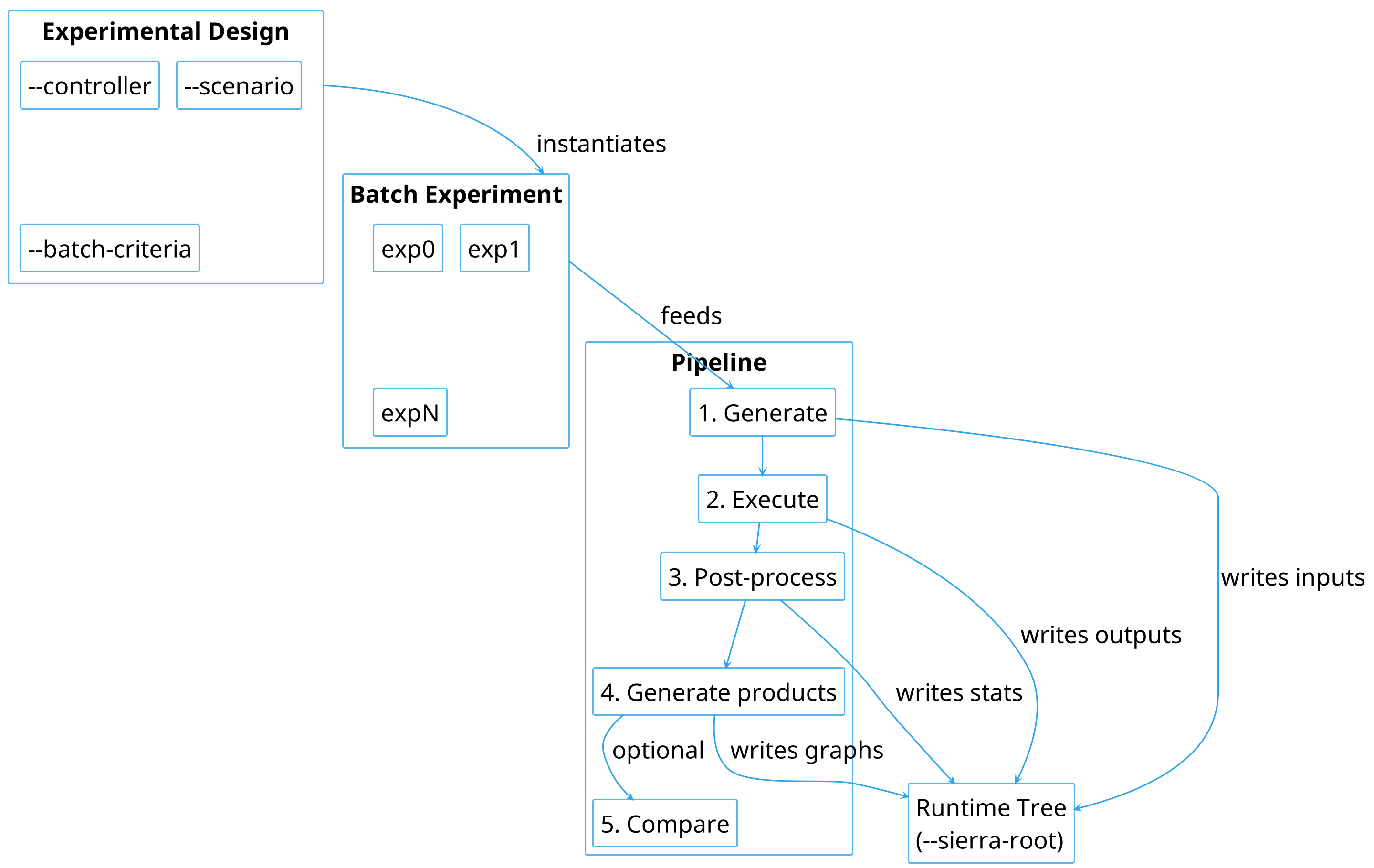
How SIERRA's core concepts relate to one another.#
How the Concepts Relate#
Experimental design is the starting point. You choose three things:
A controller — the algorithm or configuration under test.
A scenario — the environment or context it runs in.
A batch criteria — the independent variable(s) to sweep.
The batch criteria is the active ingredient. It takes your experiment template and applies a range of modifications to it — one per experiment — producing a Batch Experiment. A single criterion produces a 1-D sweep; two combined criteria produce a 2-D Cartesian product.
The pipeline then takes over. It has five ordered stages, each consuming what the previous stage produced:
Generate — transforms the template and batch criteria into individual experiment input files.
Execute — runs those inputs on the configured engine and execution environment, producing raw output files.
Post-process — reduces raw outputs across runs within each experiment into processed statistical files.
Generate products — turns processed files into graphs, videos, and other deliverables.
Compare — overlays products from multiple batch experiments for cross-controller or cross-scenario comparison. Not part of the default pipeline; run explicitly with
--pipeline 5.
Stages 1–4 are the default pipeline. Each stage is driven by one or more plugins selected on the command line; the pipeline itself is just the orchestrator.
The runtime tree is where all of this lands on disk. Every output from
every stage — inputs, raw outputs, statistics, graphs — goes under
--sierra-root, organized by project, controller, scenario, and batch
criteria. The directory names are deterministic, so re-running the same
invocation always maps to the same path. This is what makes SIERRA
reproducible: the full provenance of any result is encoded in its path.
Dataflow describes the transformations between stages. The key distinction is scope: stage 3 operates at the level of experimental runs (reducing N runs into one set of statistics per experiment), while stage 4 operates at the level of experiments (collating across experiments in a batch to produce inter-experiment products). Stage 5 then collates across batch experiments.
Where to Go Next#
If you're new, read the concepts in this order:
Experimental Design — controllers, scenarios, and how batch criteria define the parameter space.
Pipeline — what happens in each stage and which plugins are active.
Runtime Directory Tree — how to find your outputs on disk.
Dataflow Across Pipeline Stages — how data is transformed between stages.
Batch Criteria — the full detail on batch criteria syntax, directory naming, and graph types.
Once you have a mental model, Running Experiments shows how to put it into practice.