SIERRA (reSearch pIpEline for Reproducibility, Reusability, and Automation) is a command-line framework for running large-scale, reproducible computational experiments. It automates the full experimental workflow: generating experiment inputs, executing experiments across heterogeneous computing environments, collecting results, processing data, and producing analysis artifacts such as plots, videos, and comparative summaries.
SIERRA emphasizes reproducibility, automation, and reuse, allowing researchers to focus on experimental design rather than infrastructure, scripts, and environment management.
Typical use cases include robotics simulation studies, ML hyperparameter sweeps, large parameter studies in scientific computing, and automated benchmarking pipelines.
Quick Paths#
Try SIERRA immediately using the built-in sample project.
Learn how experiments, batch criteria, the pipeline, dataflow, and the runtime tree work together.
Integrate your codebase and experiment definitions with SIERRA.
The execution model, plugin system internals, and deep-dive design notes.
Add new engines, storage formats, processors, and analysis tools.
System Overview#
SIERRA organizes experimentation as a five-stage pipeline that transforms an experiment template into comparable, reproducible results — generating inputs, executing runs, post-processing outputs, producing graphs and videos, and optionally comparing across configurations. Every stage is driven by interchangeable plugins, so the same pipeline works across simulators, HPC clusters, and physical robots.
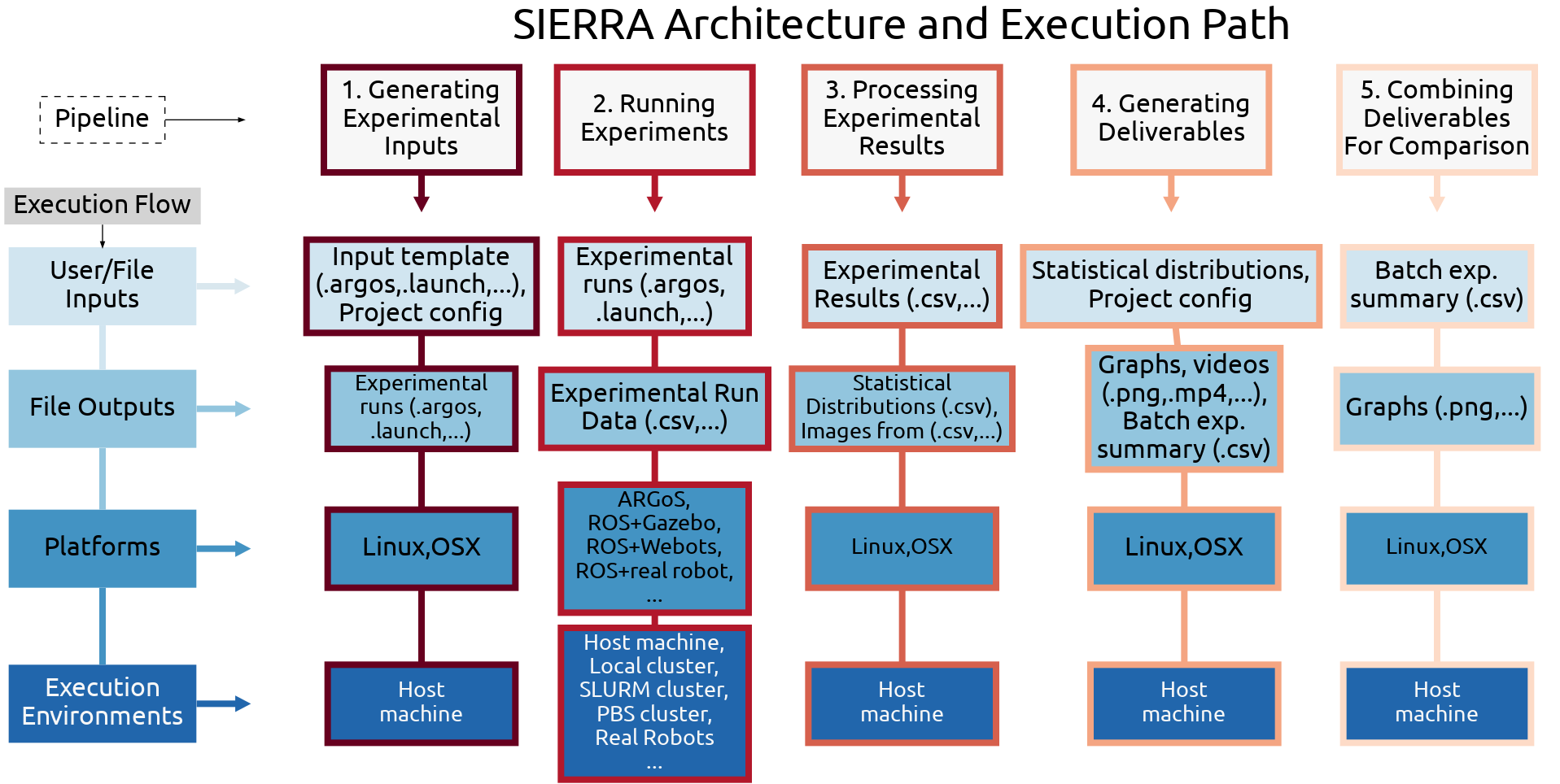
SIERRA architecture organized by pipeline stage (left to right). Each stage consumes artifacts produced by the previous stage and generates new artifacts that advance the experiment toward final results and comparisons.#
For a full explanation of how the pipeline, experimental design, runtime tree, and dataflow model fit together, see Concepts Overview.
SIERRA In The Wild#
SIERRA has been used across a range of published research in swarm robotics, multi-robot systems, and ODE-based modeling — demonstrating its flexibility across simulation platforms, scale, and experimental designs.
Papers#
Swarm Robotics & Collective Behaviour
Demystifying Emergent Intelligence and Its Effect on Performance in Large Swarms
Swarm Engineering Through Quantitative Measurement in a 10,000 Robot Swarm
Modelling & Task Allocation
Demos#
Note
Using SIERRA in your research? See Citing SIERRA for BibTeX entries and version-specific DOI badges for reproducibility.